这篇文章是为了讲解本学期《Linux 环境编程》课程的大作业《基于人脸识别自动访客识别系统》而作的。这个项目主要用 C++ 调用 OpenCV 和 dlib 写一个人脸识别的软件,类似于小区的门禁系统,要求支持流畅的实时预览和查看历史访客,剩下的可以自由发挥。
这篇文章稍微有点长,如果真的要读而不是丢给 AI 总结一下的话,笔者强烈建议放首歌边听边看,我写的时候在听王菲的《你喜欢不如我喜欢》
我是怎么起步的?
老实说我没怎么用过 C++,每次学到模板就觉得这玩意怎么这么麻烦,就没怎么学下去了。不过我改过不少 C++ 写的代码,其实大部分项目也就用到 C++ 的 class 和一些自动管理内存(RAII)的特性,所以这个作业大部分代码都是 AI 写的,我只负责 review。
在开始之前,我大概想了一想架构。
首先,预览和查看(界面)部分必须得用 Web,别用 Qt,用过你就知道和 Web 比起来多难用了。而且我也不用各种前端框架,打包、装环境很麻烦,就用纯 JS 和 CSS,反正大部分代码也就是 AI 生成,这方面问题不大。
- 写起来方便,按一下 F5 就能即时预览结果;
- AI 很会写,而且能把它写好看,Qt 要弄好看太困难了,这是我之前用 PyQt 给另一个项目弄的壳子,花了我快两天,你就看看这玩意用 Web 几分钟能还原吧;
- 这是个树莓派都能跑 Chromium 的时代,别折磨自己,
何况用 Qt 写玩脱了性能可能还不如 Web。
既然用 Web 了那肯定涉及前后端交互的问题,http 轮询和长连接都很麻烦,所以后端往前端发数据我就用到了一个叫 WebSocket 的协议。全双工、长连接、支持广泛,用起来很爽。
在 C++ 里面起一个 WebSocket 服务器需要用到一个叫 uWebSockets 的库,这个库虽然是 header-only(只包含头文件)的,但是它有一些很麻烦的依赖,而且没有给用 CMake 构建的范例,似乎作者不是很喜欢 CMake。他爽了我就不好弄了,幸好我找到另一个人提供的范例,照着改一改就跑起来了。
现在基本的技术选型都准备就绪了,我们来介绍一下后端的架构吧。
讲讲架构
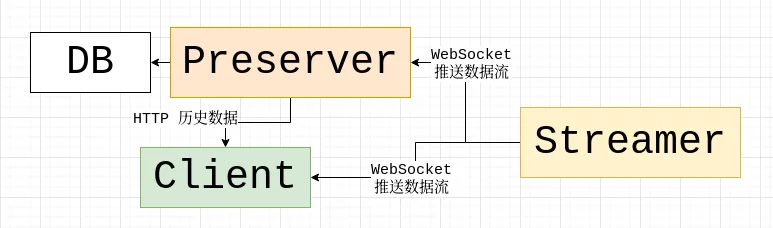
首先,后端分为两个部分,C++ 写的那部分是推流/人脸识别服务器(以下简称 streamer),还有另一部分是 Go 写的持久化服务器(简称 preserver)。
streamer 把识别到的人脸数据和采集的摄像头数据通过 WebSocket 推送给客户端(即 Web 前端或 preserver);preserver 把从 streamer 得到的数据保存到数据库里,并提供一个 RESTful HTTP API,供日后浏览。
为什么要分成这样呢?是因为我希望:
- 发挥各个语言的优势,Keep it Simple,保持代码库的精简。 streamer 已经作为一个 WebSocket 服务器监听某个端口了,那就不要在程序里又塞一个 HTTP 服务器监听另一个端口。否则上下文、日志、数据同步都非常麻烦。
- 让这个架构具有不错的可缩放性(scalability):
- 一个 preserver 可以轻松对接多个 streamer,保存来自多个不同地点的数据;
- 而用户可以既可以直接连接到 streamer,获取实时画面,又可以从一个中心化的 preserver 获取来自各各不同 streamer 的历史数据。
- 考虑到采集摄像头数据的 streamer 通常部署在性能一般的设备上,这些设备甚至可能使用 TF 卡这样的易磨损存储介质作为磁盘,并不适合直接在上面保存数据,所以我们推送到 preserver,这可能是一台家用电脑、NAS 或者云服务器,有稳定的工作环境、网络连接和较大的存储。
详细解析:streamer
streamer 的目录结构很清楚,看 include 文件夹就能看到程序的几个模块:
ConfigManager:解析 JSON 格式的配置文件,提供一个单例对象,供程序别的模块加载配置中的值。- 为什么用单例呢?因为他保证你不可能在这个模块读到的配置是这样,在另一个模块又变成那样了。
- 怎么实现呢?结合
static和 getter 方法。static保证整个程序中该变量在内存中指向的对象是唯一的,getter 方法让我们能访问到这个对象。
FaceRecognizer:人脸识别模块,主要调用其中的detect来识别人脸。Types:让 uWebSocket 开心用的。VideoStreamer:这里面就是推流相关的玩意。初始化需要通过引用绑定 WebSocket 服务器连接的客户端,然后起两个线程,一个采集数据,一个把采集的图像丢给FaceRecognizer来识别。两个线程之间通过一个队列来传递消息,经典的“生产者-消费者”模型。
详细解析:preserver
preserver 简单很多,基本就是两个功能:
- 连接到 streamer(
ws_client.go提供的服务),在有事件的时候把事件和事件发生时的图像记录到数据库里(models.go提供的服务)。 - 起一个 HTTP API(
route.go提供的服务),供用户查询数据库。
剩下的就是一些杂项服务,比方说 image.go 提供的图像处理函数,logger.go 提供的自定义格式的日志。
性能优化:摄影机不要停!
细节是魔鬼,下面是我写这玩意的时候遇到的惨痛教训,做完
我对音视频处理阴影更大了(上一次是用 FFmpeg 压字幕),希望未来不会不幸进入这个领域吧。感谢跟这些坑搏斗了一周的我。
说实话,架构定了性能上限就在那了,但是从下限到上限还有很大的距离。我第一次看到前端传过来的画面是非常兴奋的,然后我就开始写BUG加功能。
线程,我求求你别打架
最可怕的一次性能回归,发生在我引入人脸辨认(face recognize)过后,帧数从 30 帧顶满到 15 帧左右波动。为什么说可怕呢?因为这是在我已经往人脸识别的线程中,添加了一定的睡眠、减慢处理速度过后。我没有任何优化这种高负载、实时性很强的任务的经验,只会遇到困难睡大觉(this_thread::sleep_for)。所以连睡眠都没招的时候,我也不知道咋办了。
神奇的是,当我更改了睡眠的位置(之前是在两个线程末尾睡眠,现在改到推流之后、识别之前),视频流不卡了,处理器占用也下降了。我猜测原因如下:
如果我在采集数据之后同时进行推流和识别,生产者的供给会远远大于消费者能够消费的速度(采集数据很快、辨别人脸很慢),那就相当于消费者线程一直有东西可以识别,那它就会一直识别。识别需要的资源多,系统就会给这个线程调度更多的资源,给另一个线程分配相对少的资源,于是负反馈开始了:
识别线程不停地进行人脸识别 → 人脸识别计算量大,占用大量 CPU 资源 → 操作系统为了满足识别线程的需求,分配给它更多资源 → 导致采样线程资源被压缩,采样速度下降 → 采样速度变慢,识别线程获取的数据变少 → 识别任务减少,系统对识别线程的资源分配减少 → 采样线程恢复速度,采样变快 → 识别线程又开始获取更多数据,重新进入高负载状态 → …
这个过程就像一个系统内部的资源拉扯战,采样线程和识别线程在争抢资源,彼此此消彼长,最终形成一个不稳定的波动循环。它既不是简单的“某一线程太慢”,也不是“处理器性能不够”,而是没有人为设定一个速率限制点来协调生产与消费之间的节奏。
而如果我进行了上述的更改——把睡眠放到推流之后、识别之前——系统的负载就趋于均衡,视频也不再卡顿,帧数稳定在接近 30 帧。
我的理解是:这相当于我在采样线程采集到数据之后,立刻把数据推流,这一步很快完成,然后立刻睡一会儿,再继续进行耗资源的人脸识别。这样一来:
- 推流线程优先完成,保证视频不卡;
- 识别线程在推流完成之后才开始干重活,并且中间加入了主动的调节机制(sleep);
- 由于识别线程不再无脑高速消费,系统能更合理地在两个线程之间调度资源;
- 避免了前面提到的负反馈回路,资源使用变得更可控。
说到底,这其实是一个“流速配平”问题。采样-推流-识别这条流水线中,识别是瓶颈,如果你不人为限制识别的速率,它就会拖垮前面的环节。而我过去的“睡眠”只是盲目地减速,没考虑减速的位置对系统调度的影响。
这种感觉就像在高速公路上调节车速。如果你在上匝道的时候限速,那后面的车都会排队;但如果你在出口前限速,前面顺利通过,后面也容易排布。
这次经历让我认识到: 处理实时任务,尤其是高负载多线程任务时,“速率调节”本身就是一种关键能力。不是哪里卡就哪里 sleep,而是要找“对的点”来节流。
而“对的点”通常就是瓶颈所在之前的环节,或者说,是系统进入高资源消耗模式之前的那个临界点。
目标跟踪:你怎么证明我是我?
这个世界是三维的,我不确定这是不是件坏事;但它显然又不止三维,因为时间在流动。 花开花谢自有时,缘起缘落终会散…… 咳咳,有点扯远了。
为什么突然提到这个?因为画面会动,人也会动。于是,一个新的问题出现了:如何在连续的视频中,跟踪同一张人脸?
为什么要跟踪?原因很简单:
尽管我们已经把“识别这是谁”的重负丢给了另一个线程,缓解了性能压力,但这并不代表我们可以在每一帧都去执行识别。人脸识别是个资源开销非常大的任务,没必要反复问:“这是谁?”——你刚刚才识别出来,现在又在问?
现实中我们也不会这样:你认出一个人之后,只需要确认对方还在原地、没有换人就行了。你不需要在每一秒钟都重新认识他一遍。
欧氏距离,其实就是勾股定理
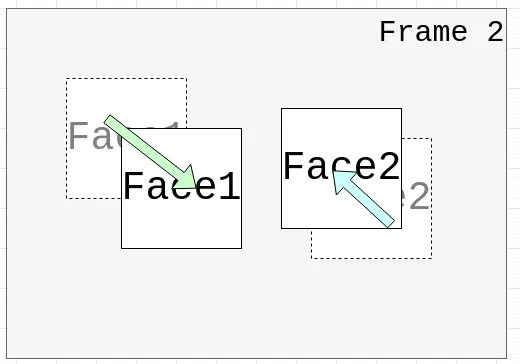
我最先想到的跟踪方法,是比较两帧之间人脸框中心点的直线距离。
假设上一帧有两个检测到的人脸框 face1 和 face2,下一帧也有两个,分别是 face1_n 和 face2_n。我们可以计算每一个旧人脸框的中心点与下一帧中所有人脸框中心点之间的距离,然后选取距离最近的那个,作为它在下一帧中的对应对象。
对于屏幕上人脸数量较少的情况,这种贪心匹配就足够用了:遍历每一个旧框,找到最近的新框,简单直接,效果不错。
但如果同一帧中出现的人脸较多,就可能出现匹配冲突(例如多个旧框都想匹配同一个新框)。这时候,就可以考虑使用匈牙利算法来进行全局最优匹配,从而最大化整体的匹配质量。(我才不会跟你讲我没看懂这个算法怎么实现所以就没敢用)
这个算法本身还有一个问题,如果两帧之间两个不同的人脸靠的太近,则会被判定成同一个人。调整阈值也没什么用,只要我贴的足够近(甚至两个人脸互相重叠),总是能触发问题的。
交并比:效果一般般
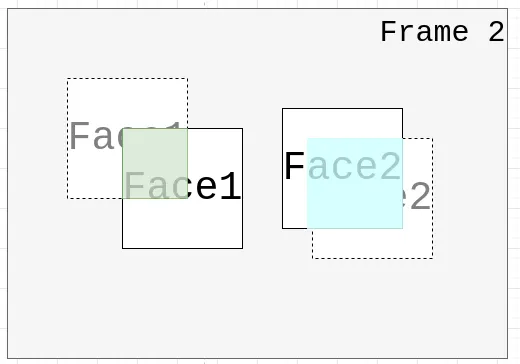
IOU 指的是 ==Intersection over Union==(交并比),在机器学习和深度学习领域,特别是目标检测和图像分割中,用于衡量两个区域或框(bounding box)的重叠程度. 简单来说,IOU 就是两个区域交集面积除以它们联集面积的比值. IOU = 交集面积/ (联集面积) IOU 的值范围从 0 到1,1 表示完全重叠,而 0 表示没有重叠. 它是目标检测算法性能评估的一个重要指标,例如,用于衡量模型预测框与真实标注框的匹配程度.
这是 Google 给出的搜索摘要。我扫了一眼描述,感觉总算走上了正道。
IOU(Intersection over Union)确实解决了我之前在判断匹配时出现的误差问题,尤其是在多目标跟踪时比质心距离更稳一点。但很快我就发现它有一个致命的缺陷:它不适用于快速移动的目标,或者说,移动幅度较大的小物体。
为什么?因为在连续两帧中,目标(比如人脸)的位移可能非常剧烈。上一帧还在左上角,下一帧就已经跳到了右下角。这时候两个框的重叠区域几乎为零,IOU 自然也就趋近于零,匹配完全失效。
我花了一个上午把这个算法接了进去,调试完一试,效果不如预期,最后还是乖乖换回了原来的基于质心距离的方法。大道至简,哈哈。
插个题外话——我在踩到这个坑之后上网查了查,结果发现不少人也被坑过。
比如这个工单:#1118 IoU is not a great fit for small/fast moving objects,是目标跟踪库 BoxMOT 的一个 issue,里面就很明确地指出了 IOU 的局限性,尤其是在处理小目标或快速移动的对象时表现不佳。
有趣的是,这个问题一直到 2024 年 1 月才开始得到缓解——他们的方法是:把质心距离也加入了匹配逻辑中,从而弥补了 IOU 在这类场景下的不足。
当然,坑还是得自己踩一遍才记得牢。亲手撞上一回,才知道现实世界里“正确的算法”也可能水土不服,这种经历也挺有意思的。
甚至自适应…?
在前面理清了生产者-消费者的关系之后,一些经验丰富的师傅建议我从“生产端供给”入手,让系统的整体性能变得更可控。于是,在 Commit 28a7131 - streamer/VideoStreamer: adaptive detection 中,我实现了自适应检测调节机制。
之前的实现方式是:推流线程和识别线程各做各的,通过线程内部的 sleep 来“各自为政”地控制负载。但问题在于,这样并没有真正建立起两者之间的联系。
而这个提交之后,逻辑发生了变化:我让推流线程每传送 N 帧图像,才往消息队列里投递一帧用于识别。 这样一来,识别的调用频率就被“锚定”在视频流的帧率上,两者形成了实际的绑定。
比如,当视频流能稳定输出 30 fps,如果我设置每 5 帧识别一次,那么识别频率就是 6 次每秒(6 tps)。 识别速率变成了一个可调的参数,可以通过配置灵活设置,既保性能,又保响应。
帽子戏法
前面讲的都是后端的优化思路。但如果你细看那句:
“当视频流能稳定输出 30 fps,如果我设置每 5 帧识别一次,那么识别频率就是 6 次每秒。”
你可能已经在心里吐槽了:等等,那画框岂不是卡成 PPT 了?延迟还巨高?
是的,没错。如果每次识别都直接把人脸框瞬移到新位置,那确实会卡得一塌糊涂,用户体验直接爆炸。
这时候,Web 的优势就体现出来了—— 你可以用 JavaScript 很方便地控制 canvas 上的绘图行为。 说白了,canvas 的绘图本质就是画点、画线,但浏览器提供的 canvas API 相比 Qt 这类传统 GUI 库,友好太多了,用起来也灵活。
我是怎么做的呢?很简单:在每次识别结果到达后,我不会立刻把人脸框“瞬间跳转”到新位置,而是让它以一定比例缓慢靠近目标。比如,当前人脸框的位置是 A,识别结果给出的位置是 B,我就让 A 每一帧往 B 靠近 30%,也就是位置更新为:
x = x * (1 - 0.3) + targetX * 0.3;
y = y * (1 - 0.3) + targetY * 0.3;这样处理后,人脸框就会“流畅地滑动”到目标位置,哪怕识别只有 6 次每秒,画面看上去仍然平稳自然,毫无割裂感。
这个思路其实就是一个非常经典的技巧:线性插值(Linear Interpolation,简称 lerp)。很多动画系统、游戏引擎都会用这个方法来平滑地过渡两个数值。
什么是 lerp?
给定一个当前值 current,一个目标值 target,还有一个介于 0 到 1 之间的系数 alpha,我们可以用下面这个公式让当前值朝目标值靠近一点点:
current = current * (1 - alpha) + target * alpha;这个过程称为“插值”或“缓动”。当 alpha=0.3 时,新的值就是往目标方向移动 30%。如果你每一帧都执行一次这个操作,值就会慢慢趋近于目标,看上去就像物体“滑”过去一样,而不是“跳”过去。
为什么它这么有效?
这其实是利用了人的视觉惯性:我们的大脑会自动补全画面中的连续性,只要“动得自然”,就不会意识到背后只有低频的数据在支撑。
它不仅让识别结果看起来更丝滑,还能减轻系统负担——你不需要帧帧做高性能人脸识别,依然能实现“动态响应”的效果。
性能优化:后记
写到这里已经有 7,500 个字了,我主要的技术亮点和优化思路都在上面。关于程序性能的可观测性,其实我都是用 top 和 pref。一个看实时的负载,也就是运行时 CPU 的占比,这个很容易能看出来优化的效果;另一个就是抓程序运行时的调用栈和他们的调用频次,比方说下面这张图就是我用 pref 监测了半分钟,再用 flamegraph.pl 生成的火焰图:
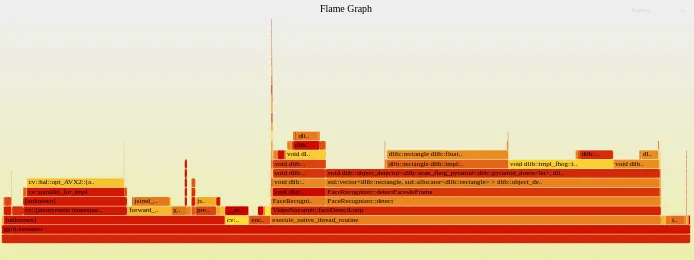
可以看到大部分调用集中在我们的人脸识别模块,其中 dlib 的人脸检测占比最多(48.51 %的 CPU 时间),而人脸辨别因为我们前述的优化,其实调用的频次很少,就是画面最右边的尖刺。
大部分 workload 都不在我能优化的范围里,愉快甩锅。
我还有什么想说的?
我高强度地在这个项目上敲了一整周,尽管最后还有一些功能没来得及实现,但瑕不掩瑜,问题不大。真心希望以后能多一些这种大作业,最好早点布置,让人有更多时间去钻研、折腾。
也感谢你读到这里,感谢你的时间和注意力。
接下来我们造什么?
下一篇”造轮子”可能是写一个高性能的 Gopher 服务器,如果你不知道 Gopher 是啥的话,这里是他的: RFC 1439 - The Internet Gopher Protocol。
你不会真的去看 RFC 吧?
好吧,其实可以理解成 HTTP 的前生,但是功能不如它强大,因为他基本上只能做”让客户端从服务器拉取某个资源和资源目录“这样的活,不支持传参这样的东西。毕竟这篇 RFC 自己都说了:Simplicity is intentional(咱是故意让这个协议这么简陋的!)
为啥要去折腾这个上古协议呢?因为实现一个 HTTP 服务器已经烂大街了,让我们来实现一个 Gopher 服务器吧。从头实现解析,处理连接,换几个不同的语言写…